Publish Date
2023-03-11

In our ever-expanding digital universe, the sheer volume of data we produce daily reminds us of our dependence on the web connectivity. For instance, online consumers spend an average of $1 billion a minute on eCommerce purchases, relinquishing information about their preferences and habits throughout their buyer's journey. The digital traces we leave behind via tweets, SMS texts, and online clicks can all amount to valuable information companies utilize for data annotation purposes, mainly through Machine Learning (ML) for Artificial Intelligence (AI) models.
In other words, data is important, especially since AI is becoming more and more popular among businesses that want to get ahead of the competition. These organizations recognize the benefits of adopting data annotation as an integral part of their business operations, where high-quality data is of utmost importance to operating at optimal levels. But having to spend valuable time and money to organize and "clean out" this data will likely be a common roadblock. Many enterprise organizations report that working with poor-quality data is one of the most prominent pain points impeding progress on their AI and ML projects. And the longer data annotation takes, the greater the bottleneck for your next product release.
Determine your priorities early in the process
So while the conversation is shifting from prioritizing big data to good data for AI companies, it's worthwhile to ask how you make this change without depleting your existing resources.
"These organizations recognize the benefits of adopting data annotation as an integral part of their business operations, where high-quality data is of utmost importance to operate at optimal levels."
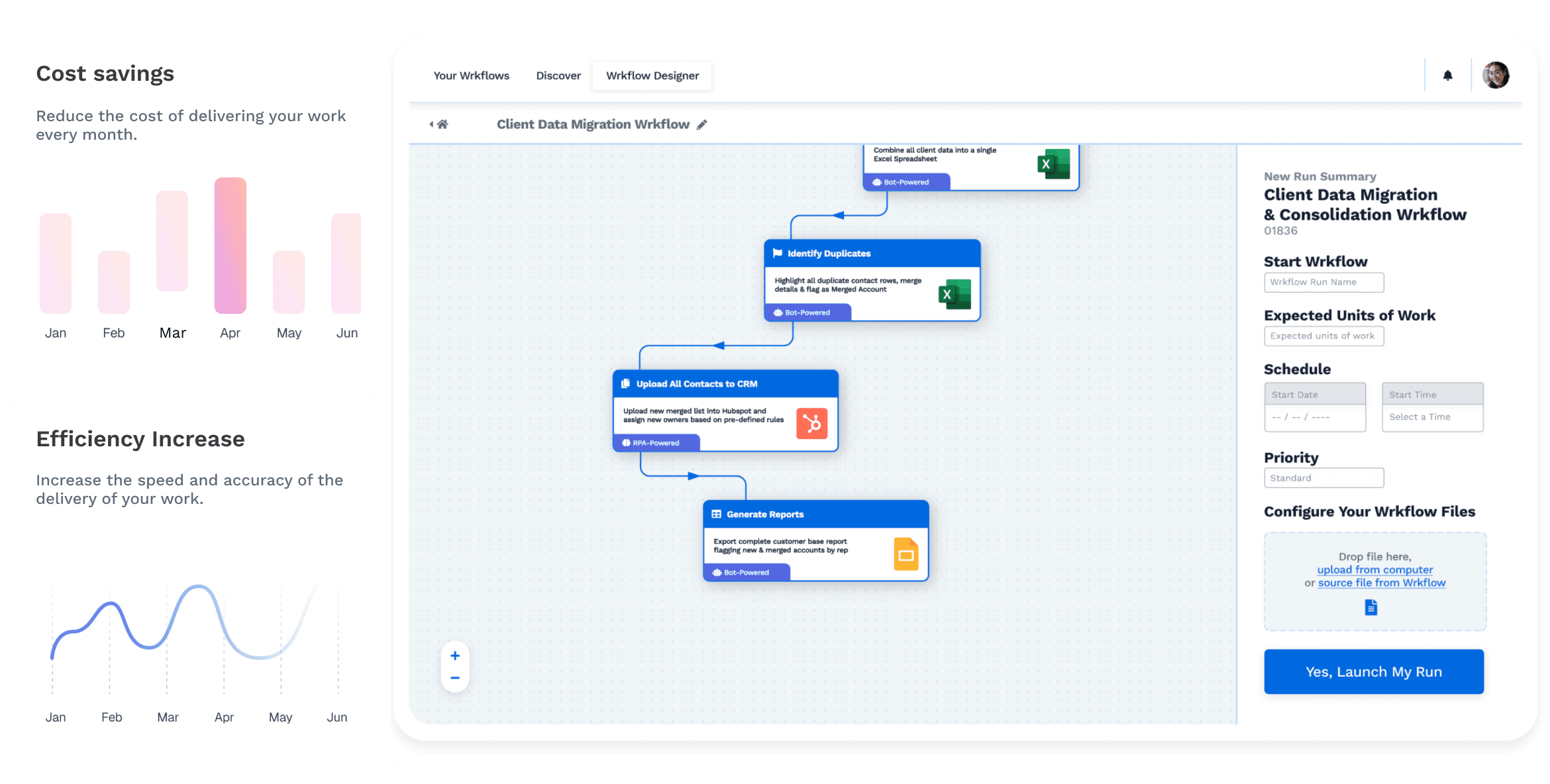
With a hybrid automation platform like Wrk, you don't have to choose between poor quality data or time-consuming processes for your team. Many hybrid platforms create manual annotation strategies that are designed with automation to empower humans. This dual "automation-human" approach results in guaranteed accuracy that expedites data annotation procedures for AI projects from start to finish, allowing your data science teams to focus on more pressing tasks - a real win-win if you ask me!
Before we go any further, if you need a quick refresher on what data annotation is, then take the time to read through the following section: What Exactly is Data Annotation? If you feel like you've already grasped the basics of data annotation, skip ahead to Value of Data Annotation in the AI Sector.
What Exactly is Data Annotation?
So, what is data annotation, anyway?
Imagine sorting through thousands of lengthy traffic cam footage to label every vehicle in the frame. That's typically what a day in the life of a data annotator looks like. It involves a meticulous process of labeling text, image, video, audio and a host of other data types to render this data legible enough for AI-powered computer systems that are programmed for supervised learning.
It's worth stressing that the labeling process itself involves humans. Data sets from unstructured sources are labeled, marked, colored, or highlighted to find differences, similarities, or patterns between them.
Once this data is annotated and ready, it's sold to companies whose data scientists need large datasets to train their ML models. Data scientists need to use clean, labeled "test" data to teach their machine learning models how to find important patterns in real-world data. When you're labeling data, you're teaching your AI system the outcome you want. You'll also teach your ML model to predict when you're ready to "feed" it real incoming data.
Data annotation is a crucial part of the data pre-processing stage during supervised learning. With enough annotated data, ML models can repeatedly identify the same patterns.
Here's a list of the most popular categories of data that are utilized by AI-powered businesses:
Text Annotation
As its name already indicates, text annotation involves deciphering unstructured text to understand what's being communicated in typed documents such as emails, chat transcripts, and online reviews. For instance, the availability of AI chatbots to deliver speedier and more efficient customer service is one example of how text annotation benefits us.
Example of Unstructured Text Annotation
Image Annotation
In image annotation, the primary goal is to render objects within an image recognizable to ML models programmed for visual perception. For instance, a dataset of images depicting people may have labeled rectangles drawn around every human element visible. Other examples include medical imagery such as x-rays, CT scans, MRIs, and ultrasounds for better disease detection and more accurate diagnoses.
Example of Multi-Label Image Annotation
Natural Language Processing (NLP)
Similarly to text, NLP annotation focuses exclusively on speech recognition for machines. Sentiment analysis of product reviews is a prominent example of the usefulness of NLP.
That was an overview of data annotation, including some of its most common use cases. But what's the real value of data annotation for AI models? Let's find out.
Value of Data Annotation to the AI Sector
Data is part and parcel of effective Machine Learning for companies embarking on AI projects. While the recent surge in the readily available data volume may seem like a blessing for data scientists who are training AI data in-house, quality matters as much, if not more, than quantity. The data training process is harder than most companies think it will be.
Many companies undertaking in-house data labeling struggle to deliver accuracy and sophistication that's becoming increasingly required to produce ML models for realistic, high-stakes scenarios, such as self-driving cars or accurate medical diagnoses.
The Merits of a Hybrid Approach
For many businesses, in-house data annotation efforts are an impediment, not a solution. Often, it detracts from the important goals of an overworked and under-resourced data science team, who would much rather spend its limited time fine-tuning and delivering meaningful models. Here, hybrid solutions are used to bridge the gap between accurate data and labor that takes a lot of time and money.
"For many businesses, in-house data annotation efforts turn out to be an impediment and not a solution."
Wrk's unique platform marries automation and a skilled workforce to speed up your annotation process. Simultaneously, it will deliver accurate and consistent results in the following ways:
Parallelization
A parallelized way of computing data lets you break big tasks into smaller ones. Automation will also speed up the annotation process. A team of skilled workers can individually solve these problems.
QA process
Wrk's hybrid system ensures that humans are involved in quality assurance. These humans double-check tasks so that your team doesn't have to. This human-on-human supervision guarantees excellent end results.
Software-empowering humans
While pure automation can handle most of your tasks, human intervention is essential to fill the gaps of edge cases. At its core, Wrk's Platform, involving highly sophisticated automation, empowers workers to solve some of their most resource-draining tasks efficiently and precisely.
A Cost-Benefit Analysis to Hybrid Automation
Wrk's hybrid platform allows skilled human labelers to manually annotate your raw data. This will be more accurate and less expensive than "pure automation" and in-house work. The benefits of a hybrid approach boil down to two important factors: skill and cost.
Let's look at both of these points a little closer.
Skill
Let's say you want to avoid the mistakes that can happen when people who label data don't know enough about their field. But you don't want to pay the cost of hiring data analysts individually. This might put a financial strain on your team. In that case, you need to consider the hybrid automation approach. Fields with "high-context" data can be hard to get right without investing in an in-house addition. Eliminate this step when you use a hybrid approach to automation and have a team ready to go.
Cost
Previous research showed that for every dollar you could spend on data labeling services from third-party providers, you spent five times that amount on internal labeling efforts. But it doesn't need to be like that. You can minimize and even eliminate these costs if you relegate the annotation process elsewhere.
Results
It's incontestable: using poor-quality data (from improperly or partially labeled data) can result in inaccurate or biased models. As the standards for accuracy get higher, you can't just use automated systems to calculate data. You'll also need the care and attention of others. That's why Wrk's hybrid automation platform boasts an impressively low margin for error. Wrk combines automation with manual annotations from its community of specialized workers. This gives you a high chance of getting accurate results that your data science teams don't need to check again.
Avoid taking in-house shortcuts that can be costly and time-consuming in the long run. Partnering with a data annotation solutions provider like Wrk can free up your team's time.
To learn more about how Wrk can help with data annotation, check out our Data Annotation Wrkflow!
Start Automating with Wrk
Kickstart your automation journey with the Wrk all-in-one automation platform